For some health plans, implementing a new payment integrity solution seems like a daunting project. They feel as though they don’t have the IT resources or expertise to get ‘data ready’ for implementation. Shift works with health plans to overcome those challenges by leveraging our own IT expertise and over 200 data scientists. We take your data in any form, and do all the heavy lifting to ensure seamless integration.
But what does Shift mean when we tell health plans that we’ll take any data in any form? We recently sat down with Shift’s Senior Product Manager of Payment Integrity Mark Starinsky, CFE to discuss how Shift helps plans tackle implementation concerns that some health plans may be unnecessarily experiencing.
Shift: Can you tell us what some of the concerns health plans have when it comes to data restrictions and data requirements when thinking about bringing in a new platform like Shift’s Improper Payment Detection?
Mark: Integrating any Payment Integrity solution can be a daunting and lengthy process with a plan’s IT department and data mapping. In most cases, vendors need health plan data in certain formats, or mapped to specific fields for the best detection results - and for many of those health plans, this can be a challenging demand. Sometimes just the idea of sharing messy, poor quality data or hosted in alternative formats can hold health plans back from working with FWA vendors - the heavy lift of conforming to restrictions or format requirements may not seem worth it. For example, they don’t know if they should use NPI or internal proprietary ID and there can be a lot of strife between the internal IT and SIUs and it can take a lot of time getting the data over to a vendor.
Shift works through those data challenges and solves for a health plan’s staffing limitations or expertise by offering a team of specialized dedicated data scientists, IT resources and customer success managers to ensure fast implementation time and ROI from day one.
Shift: What does it mean when we tell a plan to just “send us the data”?
Mark: If they just send us their claims table that’s really all we need. For the tech teams out there, all we need is an IP address that we’ll whitelist to allow a health plan to upload to an SFTP (Secure File Transfer Protocol). We have optimal files that we’d love to see but really they can just pass us data they’re already sending IT, they’re already doing that so it's nothing to send the same data to us that they're sending to their internal IT or to another vendor. We just need an export of their claims because we have our own converter that just runs through that.
Shift: When you say, ‘just send us your claims table’, is it really any kind of data?
Mark: We’d love to have as much data as possible so that we can make a better model. We ask for everything from professional claims files, behavioral health, pharmacy, dental, provider tables, member tables, but it depends on the specific data types that we agree on before we get started with a client. Sometimes certain data isn’t possible to collect or transfer, but we don’t necessarily need every piece of data to build and run our models. Regardless of the data type and files, we ask for a minimum of three years historical data transfer but sometimes we get only two years and work with that. The historical data allows us to train our models better and it meets the minimum statutory requirements for most health plans. From there we perform data cleansing, data mapping and overall prep for analysis.
Shift: What are the kinds of optimal data sources that you mentioned before?
Mark: While we can take all kinds of data, we do in fact have optimal sources but they’re certainly not required. Our top 5 data sources would be claims data, beneficiary or patient data, plan policy data, provider data and case management data. And we don’t even need data to be mapped. We do that and can get raw data in a spreadsheet if that’s what the plans have to give us. Combined with Shift’s integration of external data, these sources help investigators get the best view of activity within a plan.
Shift: Once you get the data from the health plan, what happens and what is the process?
Mark: We’ll get the infrastructure and server set up in no time to receive the data and get to work on data validation and mapping right away. Then we go to work on the model configuration with our data scientists and they are choosing the best models possible so that it works best for the customer. After that, the customer will be able to access the UI and work on acceptance testing. This is the fun part where customers get to see it, touch it, play and see how it works for them. From there we go live and the customer starts seeing results from day one of go live.
Shift: What does it mean to map and cleanse data? Where does Shift’s AI help in this process?
Mark: From a data cleansing perspective, we’re looking for data that is incomplete, inaccurate or irrelevant and then replacing it with updated, modified and accurate data. We’ll be deleting and formatting where we need to to make sure that it’s configured correctly. Our AI-powered entity resolution automates the process of finding duplicates, multiple variations or misspelled provider data.
Shift: What is entity resolution? Where does this come into the data mapping process?
Mark: Claims data can be littered with duplicates, alternate IDs, alternate names, misspellings, you name it - these can be mistakes in the data, but also opportunities for bad actors to bill under multiple entities when they in fact, are the same. Where analysts can spend hours matching addresses, NPI data, or other points - Shift’s AI-powered entity resolution automates this step to ensure investigators are focusing on the right cases.
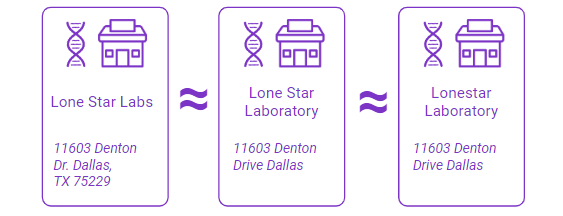
All of what Shift does helps the SIU team and,in turn, the overall plan to work more efficiently and to save money from the first day of implementation. With the advanced AI and team of data scientists at Shift, there really is no reason that health plans should feel compelled to do any heavy lifting at all.
And much of the work that we do with our data, saves the SIU hours, days, weeks of lost time while they research claims or providers.


