The State of AI in Insurance (Vol. II): A Comparison of LLMs
Executive Summary
- The LLM market is rapidly evolving, with various models now available which are appropriate for a variety of use cases
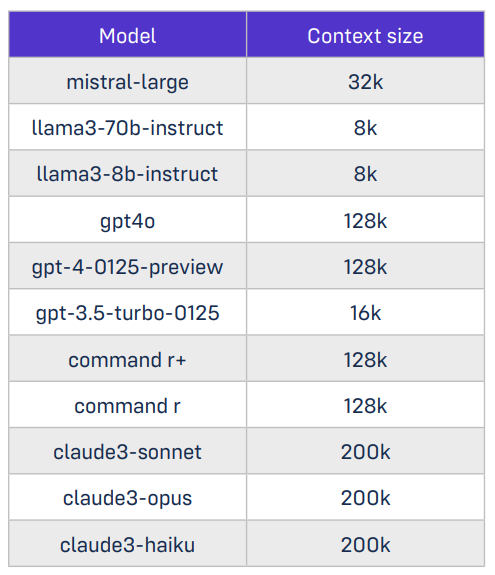
- Determining which LLM is best for which use case involves comparing context size, overall cost and performance
- Focused prompt engineering and tuning can be the difference between exceptional and disappointing performance
From the editor
Advances in the use of artificial intelligence (AI) and generative artificial intelligence (GenAI) to improve critical insurance processes continue to captivate the industry. At the same time, it can be incredibly difficult to navigate the rapidly changing landscape and make the best decision about how to implement these innovations to reap the best results.
In the inaugural The State of AI in Insurance report, we explored the performance of six different Large Language Models (LLMs) when applied against several insurance-specific use cases. Shift data scientists and researchers sought not only to compare relative performance against a set of predetermined tasks, but also illustrate the cost/performance comparisons associated with each of the LLMs tested.
In Vol. II, we are testing eight new LLMs and have retired two that appeared in the previous report. The newly tested models include Llama3-8b, Llama3-70b, GPT4o, Command r, Command r+, Claude3 Opus, Claude3 Sonnet, and Claude3 Haiku. The Llama2 models which appeared in the inaugural report have been removed from the comparison and replaced with the Llama3 models. Llama3 models are more representative of the current state-of-the-art for available LLMs.
Further, the report now features a new table highlighting an F1 score generated for each model. For this report the F1 score aggregates coverage and accuracy against two axes - the specific use case (e.g. French-language Dental Invoices) as well as the individual fields associated with the use case. The approach allows us to generate a single performance metric per use case as well as an aggregated overall score including the cost associated with analyzing 100,000 documents. The following formula was used to generate the F1 score: 2 x Cov x Acc / (Cov + Acc).
Thank you to the Shift data science and research teams that make this report possible.
LLM Model Comparison for Information Extraction, Select Insurance Documents
Methodology
The data science and research teams devised four test scenarios to evaluate the performance of 11 different
publicly available LLMs: GPT3.5, GPT4, GPT4o, Mistral Large, Llama3-8b, Llama3-70b, Command r, Command r+,
Claude3 Opus, Claude3 Sonnet, and Claude3 Haiku.
The scenarios include:
- Information extraction from English-language airline invoices
- Information extraction from Japanese-language property repair quotes
- Information extraction from French-language dental invoices
- Document classification of English-language documents associated with travel insurance claims
The LLMs were tested for:
- Coverage - did the LLM in fact, extract data when the ground truth (the value we expect when we ask a model to
predict something) showed that there was something to extract. - Accuracy - did the LLM present the correct information when something was extracted.
Prompt engineering for all scenarios was undertaken by the Shift data science and research teams. For each individual scenario, a single prompt was engineered and used by all of the tested LLMs. It is important to note that all the prompts were tuned for the GPT LLMs, which in some cases may impact measured performance.
Reading the Tables
Evaluating LLM performance is based on the specific use case and the relative performance achieved. The tables included in this report reflect that reality and are color-coded based on relative performance of the LLM applied to the use case, with shades of blue representing the highest relative performance levels, shades of red representing subpar relative performance for the use case, and shades of white representing average relative performance.
As such, a performance rating of 90% may be coded red when 90% is the lowest performance rating for the range associated with the specific use case. And while 90% performance may be acceptable given the use case, it is still rated subpar relative to how the other LLMs performed the defined task.
Results & analysis
English-language Airline Invoices
In this scenario, the LLMs being tested analyzed 85 anonymized English-language invoices.
The extraction prompt sought the following results:
- Provider Name
- Start Date
- End Date
- Document Date
- Booking Number
- Flight Numbers (list of all flight numbers)
- Credit Card 4 Last Digits
- Currency
- Basic Fare All Passengers
- Taxes And Fees All Passengers (list of all taxes and fees)
- Additional Fees All Passengers (list of additional fees)
- Total Amount
- Total Paid Amount
- Payments (complex field: list of Payment, object containing the following fields: Payment Date, Amount, Status)
- Travellers (complex field: list of Traveller, object containing the following fields: Traveller Name, Basic Fare, Total Taxes, Total Amount)


Analysis
The introduction of the new LLMs into the testing environment produced several interesting results. On what have been classified as “simple fields,” which we define as fields containing simple data types such as date, type, amount, and other fields whose value is unique and not a list of elements, GPT4o, GPT4, and Claude3 Opus outperformed all of the other models with GPT4o leading the top three contenders. There is however one exception. In the case of Total Paid Amount coverage, GPT4o underperformed relative to the other two leading LLMs. The reason for this exception is not immediately evident and will require additional research and experimentation to determine the cause.
Claude3 Sonnet, Mistral Large, Command r+ and Command r demonstrated performance close to, but still slightly behind the leading LLMs. And finally, the Llama3 models, GPT3.5 and Claude3 Haiku performed similarly, but behindbthe seven leading models. We do witness that the performance gap highlighted in the inaugural report between the Llama2 models and the other models has tightened significantly with the introduction of Llama3 into the testing. This may be due to the larger base context size (4k vs. 8k) for Llama3.
For what have been identified as “complex fields,” which we define as fields that represent complex objects or whose value is a list of objects, we find that GPT4 and Claude3 Opus are the best models for these particular tasks, with GPT4 slightly outperforming Claude3 Opus.
Claude3 (both Sonnet and Haiku), Mistral Large and Llama3-70b did not perform as well as what would be considered the leading models. Interestingly we find that performance for these models is highly dependent on which field is being analyzed with our research showing that each model slightly outperforms the others depending on the particular data requested.
Finally, in this scenario we found GPT4o to be very good in terms of accuracy but surprisingly bad in terms of coverage. While this may imply that the model is not able to retrieve complex information, it may simply indicate that prompt engineering/tuning on these fields would most likely fix the issue.
Japanese-language property repair quotes
We evaluated 100 anonymized Japanese property repair quotes associated with different service providers. The format of these documents were not standardized.
The extraction prompt requested data from the following fields:
- Provider Name
- Provider Address
- Post Code
- Provider email
- Tax Amount
- Total Amount with Tax
- Discount Amount

Analysis
Overall, GPT4o, GPT4, Mistral and Claude3 (Opus and Sonnet) performed best in this scenario with all achieving similar results.
We witnessed a small degradation of performance related to GPT3.5, Claude3 Haiku and Llama3-70b. And while these models did achieve equivalent performances on most fields, underperformance on others impacted the assessment.
Command r, Command r+ and Llama3-8b models performed well enough in comparison to other models when considering coverage. However, they are clearly behind when assessing accuracy. That could indicate that these models have a difficult time with the Japanese language and we intended to further investigate this phenomenon.
On initial examination, the accuracy on textual fields (e.g. Provider Name, Provider Address, Provider Email) may seem a bit low. However, it is not entirely unexpected seeing that it is impossible to validate the output of the model with a structured format in the same way that you can for amounts or dates as those particular metrics are very strict and require the ground truth and prediction to be exactly the same.
We are surprised with the consistent underperformance of the fields Post Code and Discount Amount across all models. It is not apparent what would cause this. Further investigation will be conducted.
French-language dental invoices
For this scenario we applied the LLMs being tested against 119 anonymized French dental invoices. 79 of which would be considered templated with the remaining 60 invoices were randomly selected. The resulting dataset would be described as approximately 60 percent templated. This methodology was selected to best represent a typical dental insurance provider’s dataset.
We asked each LLM to extract the following:
- Document Date
- Provider Name
- Raw Provider FINESS (Fichier National des Établissements Sanitaires et Sociaux)
- Raw Provider RPPS (Répertoire Partagé des Professionnels de Santé)
- Provider Post Code
- Total Incurred Amount
- Paid Amount

Analysis
GPT4o, GPT4, and Claude3 (all versions) performed best overall in this scenario and all demonstrated similar performance. However, it should be noted that GPT4o and Claude3 Opus are extremely close in terms of performance, and slightly outperform the other models.
We find that Command r+, Llama3-70b and Mistral Large are comparable to GPT3.5 while the other Llama models and Command r lag.
The witnessed underperformance for the field Provider FINESS (an identifier associated with the national directory managed by the digital health agency) could be due to the fact that French health invoices do not always clearly identify the FINESS or other provider identifiers (AM or SIRET). This confusion could impact the models’ ability to retrieve the information but also the quality of the ground truths for this field.
English-language documents for travel claims
This scenario used 405 anonymized English-language documents provided in support of travel claims.
The prompt will ask the model to:
- Classify each page
- Group the pages related to the same document (as several documents can be located in a same file)
- Output each file as a list of segmented documents, where each element contains the document type and a span indicating the start and end page in the file
As with the other scenarios, we report the typical coverage and accuracy metrics for each document type individually. In addition, we include two aggregated metrics:
- Perfect Classif: Here we consider an output of the model correct when all the segmented documents in a file are
error-free (document type and page span) - Perfect Types: Here we consider an output of the model correct when all the document types in a file are errorfree (meaning there could be errors in the page spans)(PerfectTypes)
As with the other scenarios, we report the typical coverage and accuracy It is important to note that between the inaugural report and Vol. 2 the prompt for this scenario was tuned slightly. After generating surprising underperformance for GPT4o, our investigation uncovered an error in the prompt. Specifically we were asking the model to output a “markdown JSON" instead of a “JSON” which resulted in the addition of a separator that we were not expecting and were not parsing properly. The prompt was tuned to fix this and another slight ordering error.


Analysis
The refined prompt engineering solved the GPT4o underperformance issue. It did not materially impact the performance metrics of the other LLMs tested, with the exception of Mistral Large and Llam3-70b.
GPT4 and GPT3.5 performances are stable after the prompt modification and demonstrated excellent performance, with GPT4 slightly below GPT4o and GPT3.5 behind that.
Llama3-70b benefited from a 10 percent coverage boost and demonstrated stable accuracy, which makes it comparable to GPT3.5.
Command r+ and Command r coverage and accuracy performance is more consistent across fields following prompt tuning. Command r+ performance is comparable with GPT3.5 and Llama3-70b with Command r slightly behind.
Prompt engineering did generate some unexpected results associated with Mistral Large. While coverage was similar to that of GPT4 and GPT4o, accuracy would be considered disappointing. Additional investigation revealed that the underperformance can be attributed to insurance forms for which the model does not follow the expected naming. And while this indicates the documents could easily be reclassified correctly in post processing it is also surprising that the model is not able to output the correct name for these documents.
The F1 Score and Conclusions

Based on our testing we can offer the following analysis and conclusions.
Relating to information extraction tasks with what could be considered simple fields it is clear that GPT4o, GPT4, and Claude3 (Opus, Sonnet, Haiku) are the best performing models and fall within the same performance range on all fields.
GPT3.5, Mistral Large and Llama3-70b are comparable to the best performing models with the primary difference being inconsistency in performance between fields. We also found that Llama3-8b, Command r+ and Command r are overall comparable to GPT3.5 but also underperforms on some specific fields.
For those tasks associated with complex fields we see that GPT4 and Claude3 Opus are the best models, with GPT4 slightly outperforming Claude3 Opus.
Claude3 (Sonnet and Haiku), Mistral Large and Llama3-70b lag slightly behind the leaders with each model slightly outperforming the others depending on the field being analyzed.
For what are identified as classification tasks GPT4o, GPT4 and Claude3 (Opus and Sonnet) produced the best results with GPT4o slightly outperforming the others.
GPT3.5, Llama3-70b, Command r+ and Claude3 Haiku show some slightly diminished performance when compared with the leaders, while Llama3-8b and Command r clearly underperform.

However, when evaluating LLMs it is critically important to not only evaluate overall performance, but also performance related to cost. As we see in the above cost comparison chart as well as the F1 table, the highest performing models typically boast the highest costs. However, depending on the use case, it may be permissible to sacrifice some performance for economy. For example, Claude3 Opus is highly performant, but may also be prohibitively expensive. GPT4o and Claude3 Sonnet deliver excellent performance at a slightly more affordable price point while our analysis shows that GPT3.5-turbo and Claude3 Haiku delivers an admirable combination of price and performance.
The realm of GenAI and LLMs is rapidly evolving. This report is intended to provide an unbiased evaluation to help
readers make the best decision possible about how to make this technology a part of their technology strategy.


