The State of AI in Insurance (Vol. VIII): 推論(Reasoning) モデル
エグゼクティブサマリー
- 「推論(reasoning)」とは、LLMが応答を返す前に内部で“思考”する能力を指します。
- 推論能力は、より複雑な業務に適用した場合にとくに有用です。
- これまでの知見と同様に、本調査でも推論モデルの性能は適用するユースケースに大きく依存することが示されました。
- 推論モデルの選択や「推論の深さ(reasoning effort)」の設定は、求められる性能、コスト、応答遅延(レイテンシ)などの要因によって決まります。
編集部より
本号の「The State of AI in Insurance」では、データサイエンスおよびリサーチチームが OpenAI と Anthropic が提供する推論モデルを詳細に検証しました。推論モデルは、LLMが応答を出す前に内部で“考える”ことを可能にし、理論的には複雑な業務での精度や効率を高めることを狙っています。
私たちは以前の調査(The State of AI in Insurance: Vol. VI — Claims Decisioning and Liability Determination in Subrogation)で、推論モデルは、単純なケースでも複雑なケースでも高い性能を示すことが確認されました。ただし、高性能であるがゆえにコストや応答遅延(レイテンシ)が増える傾向があり、そのため単純なデータ抽出や分類には必ずしも最適ではないという課題も明らかになりました。
本調査では推論モデルの性能検証を続ける一方で、今回新たに「推論の深さ(reasoning effort)」という概念に注目しました。これはモデル内部の“思考”の深さを調整できる機能で、OpenAI の初期 o‑series 推論モデルでは選択可能でしたが、我々の従来検証では中(medium)設定のみで評価していました。本レポートでは、最小(minimal)・低(low)・中(medium)・高(high)の各推論深度設定が、主要ユースケースに与える影響を比較しています。
保険関連文書からの情報抽出・分類に関するLLM推論モデル比較
方法論
データサイエンスおよびリサーチチームは、6つのテストシナリオを用い、公開されている推論モデル10種の性能を評価しました。うち4シナリオは抽出・分類タスクに分類され、残る2シナリオ(Claims Decisions と Motor Liability)は明確に推論タスクとして定義しています。
- 英語の航空会社請求書からの情報抽出(複雑)
- 日本語の住宅修理見積書からの情報抽出(単純)
- フランス語の歯科請求書からの情報抽出(単純)
- 旅行保険に関する英語文書の分類(複雑)
- 保険金請求の有無責判定(推論タスク)
- 自動車事故の損害賠償責任(Motor Liability:推論タスク)
保険金請求判定シナリオの定義 — モデルが以下の判断を行えるかどうかを検証する:
- 申告は保険の有効期間内か?
- 請求書は申告内容と整合しているか?
- 申告内容に基づいて却下すべき理由はあるか?
- 補償や支払判断に必要な情報が欠けていないか?
- 保険金請求のステータス判定(例:保留、承認、却下)
- もし補償対象であれば、総額でいくら支払うべきか?
自動車事故の損害賠償責任シナリオの定義
- 保険金請求に含まれる情報から、代位求償(サブロゲーション)判断に必要な責任の所在を特定できるか?
評価指標:
テスト対象の LLM について以下を評価
- Coverage(抽出対象の網羅性) — 期待される値に抽出対象が存在する場合、モデルはそれを抽出できたか。
- Accuracy(正確性) — 抽出した情報が正しかったか。
コストに関する注意点
標準的なモデルについては、10万件の書類処理を想定したコスト見積もりを行う際、出力側のトークン量を0.5k(=約500トークン)と仮定しています。推論(reasoning)型のモデルは出力トークンが増える傾向にあるため、コスト見積もりでは出力トークン数に対して以下の乗数を適用しています。
- Minimal: 1.0
- Low: 1.5
- Medium: 2.0
- High: 3.0
表の読み方について
LLM(大規模言語モデル)の性能評価は、目的となるユースケースごとに行います。本レポートの表はその前提に基づき、各モデルが当該ユースケースでどの程度相対的に優れているかを色分けで示しています。色は以下の意味合いです。
青系:当該ユースケースでの相対的な高性能
白系:平均的な性能
赤系:当該ユースケースでは相対的に低い性能
そのため、例えば「90%」という数値が示されていても、同ユースケース内で他モデルがより高い値(例えば95%や98%)を出していれば、相対評価としては赤(低め)に表示されることがあります。つまり、あるモデルの絶対的な性能は「許容できる水準」であっても、同じタスクで他のモデルがさらに良い結果を出している場合は「相対的に劣る」と評価される可能性がある点にご留意ください。
結果
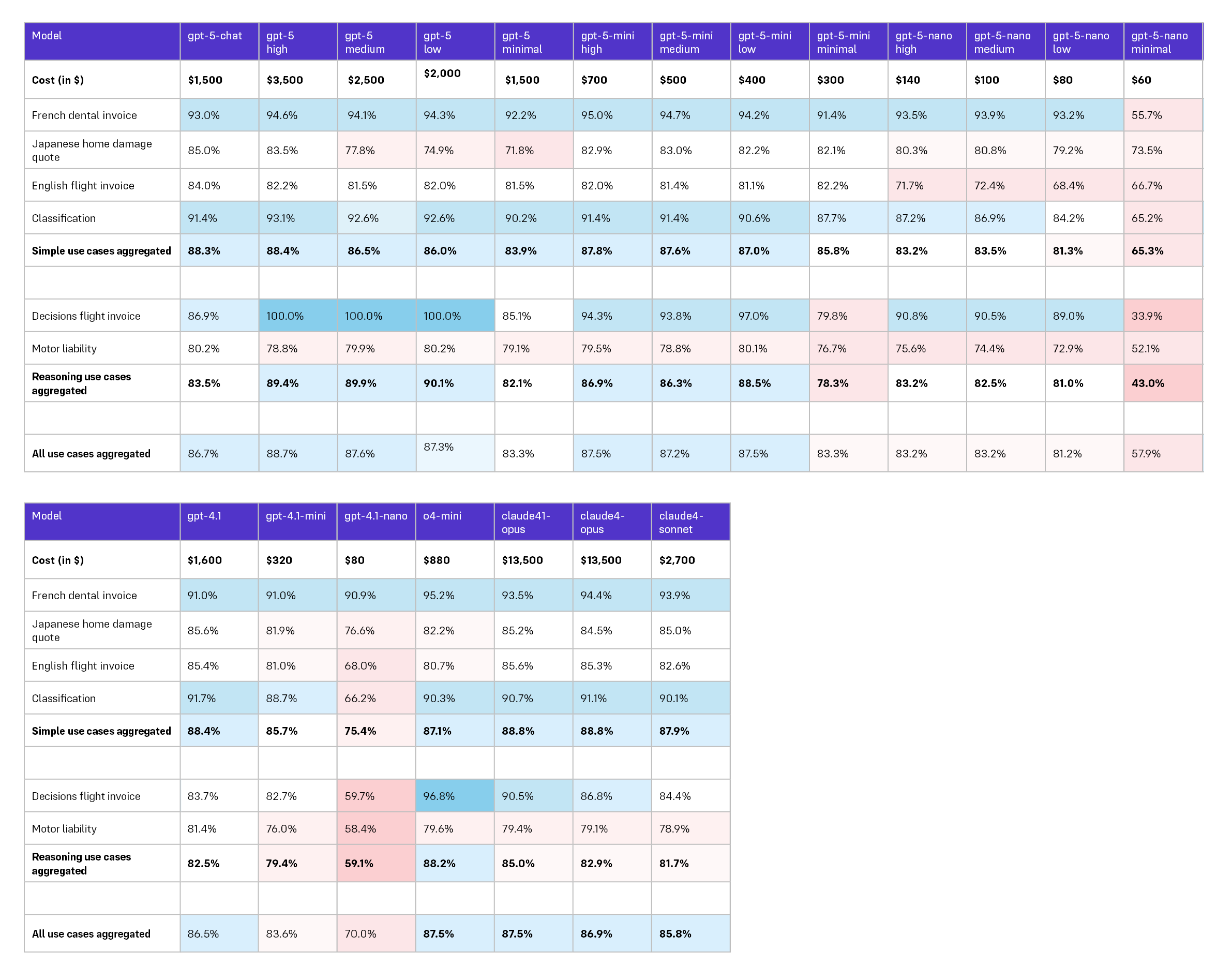
分析
GPT‑5 ファミリー:本検証では、GPT‑5 は推論タスクで優れた性能を示す一方、より単純あるいは構造化されたユースケースではやや劣後する傾向が見られました。興味深いことに、これは以前 o4‑mini(純粋な推論モデル)を評価した際の振る舞いと類似しています。GPT‑5 はしばしば「汎用モデル」と見なされますが、今回の検証ではしばしば推論モデル的な振る舞いを示しました。したがって、GPT‑5 は複雑な推論ワークフロー向けに理想的ですが、単純な抽出や分類を行う場合はより適した代替モデルがあると考えられます。
GPT‑5‑mini の性能は、ほとんどのユースケースにおける魅力的なベースラインとして評価できます。出力品質は優れた汎用モデルと同等のレンジに位置しつつ、メインラインの GPT‑5 よりもコスト効率が高い点が利点です。ただし、デフォルトでは推論深度(reasoning effort)を「low(低)」に設定することを推奨し、レイテンシやコストに余裕がある場合にのみ「medium(中)」を検討するとよいでしょう。「high(高)」の設定は通常は推奨されません。
コスト面で魅力的な GPT‑5‑nano については、構造化抽出や意思決定タスクにおいて明確なトレードオフ(品質低下)があるため、コスト最優先で品質要件が低い場合に限定しての採用を推奨します。
OpenAI の既存ライン(GPT‑4.1 等)と o4‑mini:我々の検証では、GPT‑4.1 は単純タスクにおいて引き続き信頼できる選択肢であり、コストパフォーマンスにも優れています。また o4‑mini は依然として強力な推論モデルの選択肢であると評価します。しかし、GPT‑5‑mini のバランスの良さを踏まえると、まずは GPT‑5‑mini(推論深度を low に設定)を評価対象とし、それでも要件を満たさない場合により重い推論モデルへ進む、という順序が現実的と考えます。
Anthropic(クロード)について:Claude 4.1 Opus は以前の Claude バージョンから改善が見られますが、今回のユースケースの組み合わせにおいては、そのプレミアム価格を正当化するほどの上乗せ効果は限定的でした。Anthropic ラインナップ内では Sonnet がコスト面で現実的な選択肢として残ります。
結論
Shift の研究は、LLM の性能およびどの LLM を活用するのが適切かは、その適用ユースケースに本質的に依存することを改めて示しています。LLM を採用する組織は、望ましい性能レベル、許容可能なレイテンシ、およびコストを十分に理解したうえで最適な選択を行う必要があります。一見すると「より大きいモデルがより良い」と考えがちですが、本調査の結果はその仮定が多くの場合において誤りであることを示しています。

